以前其他版本的AlphaGo,都經過人類知識的訓練,它們被告知人類高手如何下棋。而最新發布的AlphaGo Zero使用了更多原理和算法,從0開始,使用隨機招式,40天后成為圍棋界的絕世高手。真真正正的自學成才。
新的AlphaGo Zero使用了一種全新的強化學習方式,從0基礎的神經網絡開始,與搜索算法結合,不斷進化調整、迭代升級。AlphaGo Zero的不同之處在于:
除了黑白棋子,沒有其他人類教給AlphaGo Zero怎么下棋。而之前的AlphaGo包含少量人工設計的特征。
AlphaGo Zero只用了一個神經網絡,而不是兩個。以前AlphaGo是由“策略網絡”和“價值網絡”來共同確定如何落子。
AlphaGo Zero依賴神經網絡來評估落子位置,而不使用rollouts——這是其他圍棋程序使用的快速、隨機游戲,用來預測哪一方會獲勝。
創新工場AI工程院副院長王詠剛用“大道至簡”四個字評價新版的AlphaGo Zero。
上述種種,讓AlphaGo Zero異常強大。
“人們一般認為機器學習就是關于大數據和海量計算,但是DeepMind通過AlphaGo Zero的案例發現,算法比計算或者數據可用性更重要”,AlphaGo團隊負責人席爾瓦(Dave Silver)介紹說,AlphaGo Zero的計算,比之前的AlphaGo減少了一個數量級。
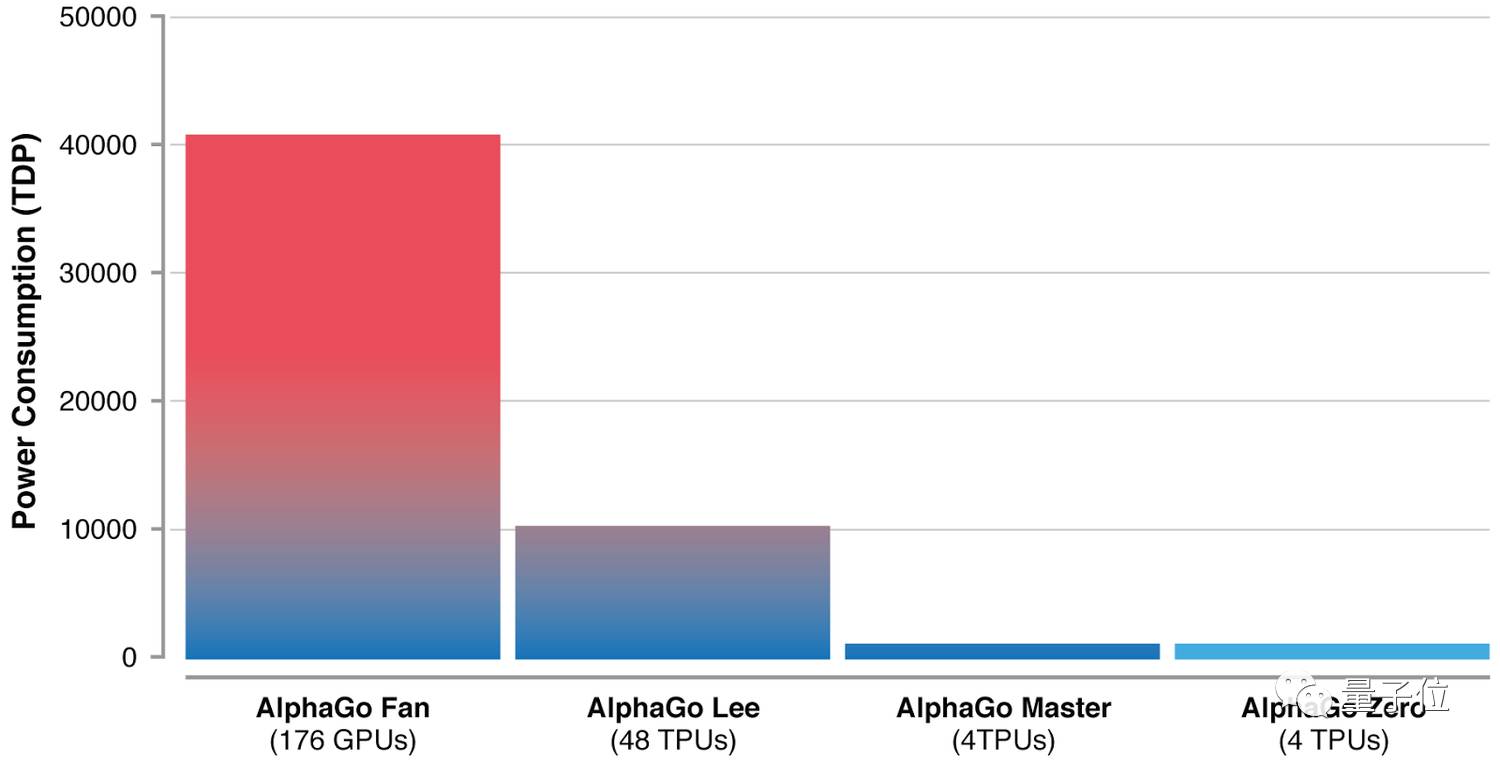
如上圖所示,AlphaGo Zero也只用了4個TPU。
AlphaGo Zero到底多厲害,且看官方公布的成績單:
3小時后,AlphaGo Zero成功入門圍棋。
僅僅36小時后,AlphaGo Zero就摸索出所有基本而且重要的圍棋知識,以100:0的戰績,碾壓了當年擊敗李世乭的AlphaGo v18版本。





















 營業執照公示信息
營業執照公示信息