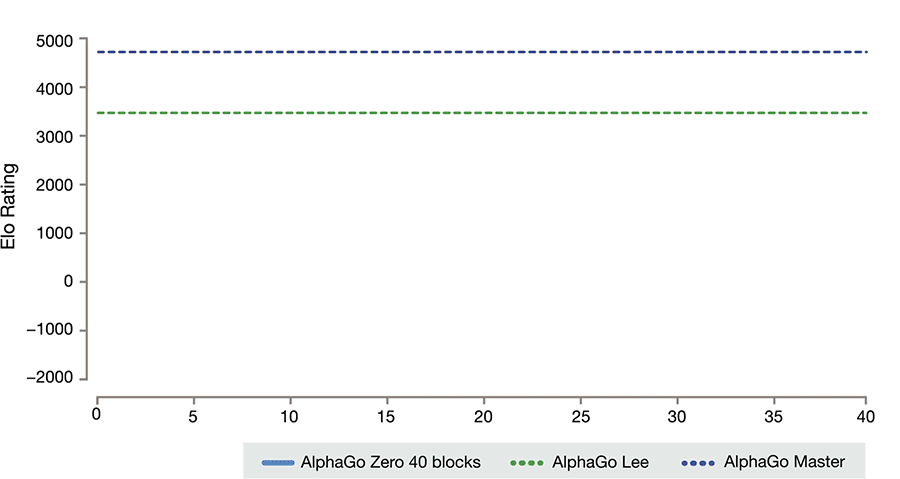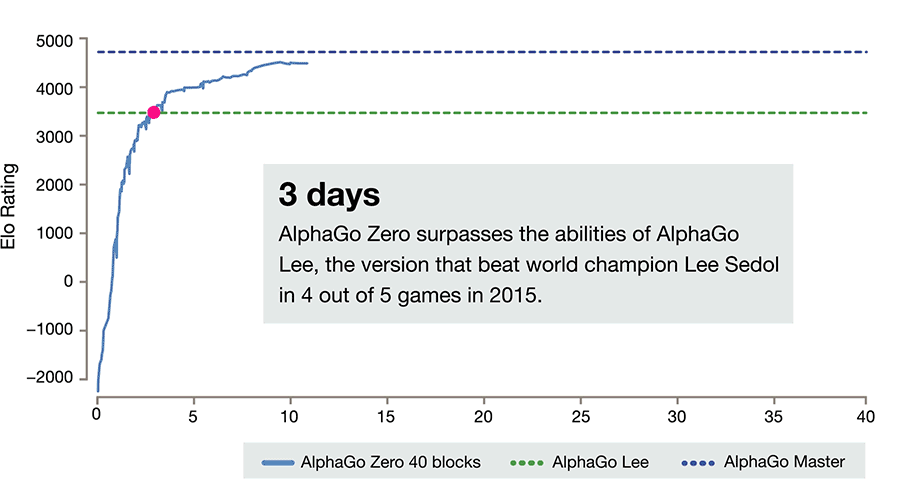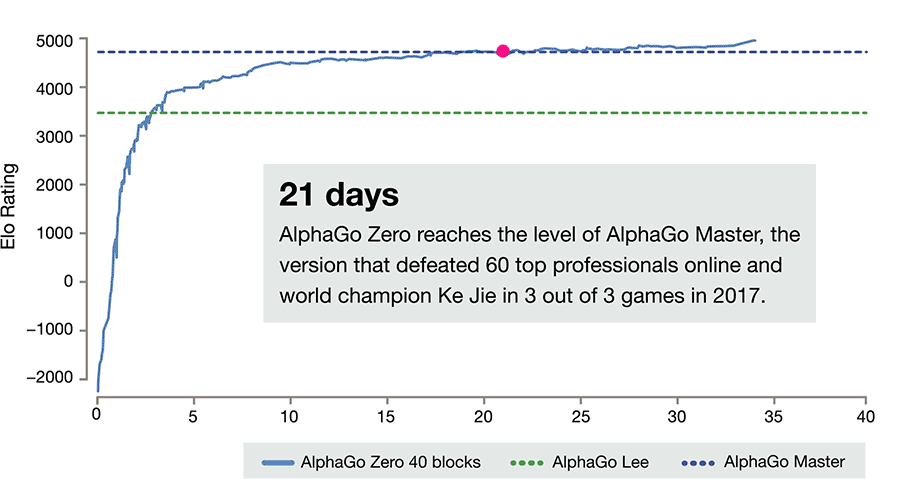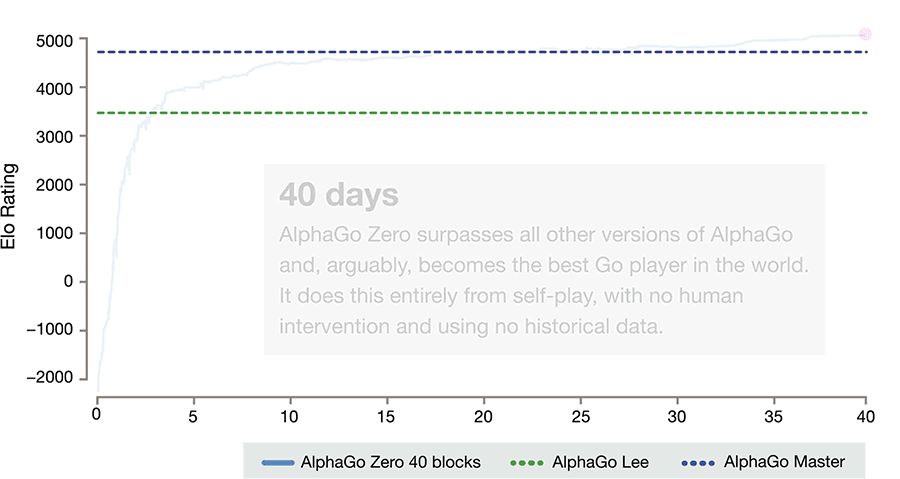
21天后,AlphaGo Zero達到了Master的水平。這也就是年初在網上60連勝橫掃圍棋界的版本。Master后來擊敗了柯潔。
40天后,AlphaGo Zero對戰Master的勝率達到90%。也就是說,AlphaGo Zero成為寂寞無敵的最強圍棋AI。
DeepMind主要作者之一的黃士杰博士總結:AlphaGo Zero完全從零開始,初始階段甚至會填真眼自殺。AlphaGo Zero自學而成的圍棋知識,例如打劫、征子、棋形、布局先下在角等等,都與人類的圍棋觀念一致。
“間接呼應了人類幾千年依賴圍棋研究的價值”,黃士杰寫道。

技術細節
DeepMind的最新研究成果,已經全文發布在《自然》雜志上。這也是第二篇在《自然》雜志上發表的AlphaGo論文。
論文摘要
人工智能的長期目標是創造一個會學習的算法,能在特定領域中從一塊白板開始,超越人類。最近,AlphaGo成為第一個在圍棋游戲中打敗世界冠軍的程序。AlphaGo中的樹搜索使用深度神經網絡來評估位置、選擇落子。這些神經網絡用人類專家的棋譜來進行監督學習的訓練,并通過自我對弈來進行強化學習。本文介紹了一種僅基于強化學習的方法,除了游戲規則之外,沒有人類的數據、指導或者領域知識。AlphaGo成了它自己的老師:一個被訓練來預測AlphaGo自己落子選擇以及對弈結果的神經網絡。這個神經網絡提高了樹搜索的強度,提高了落子質量、增強了自我對弈迭代的能力。從一塊白板開始,我們的新程序AlphaGo Zero的表現超越了人類,并以100-10擊敗了以前曾打敗世界冠軍的AlphaGo版本。





















 營業執照公示信息
營業執照公示信息