圖c顯示了更新行為價(jià)值Q以追蹤該行為下面子樹(shù)中所有評(píng)估V的平均值。
圖d顯示,搜索完成后,搜索概率π返回,與N1/τ成比例,其中N是從根狀態(tài)每次移動(dòng)的訪問(wèn)次數(shù),τ是控制溫度的參數(shù)。
從零開(kāi)始的訓(xùn)練
DeepMind在論文中表示,應(yīng)用了強(qiáng)化學(xué)習(xí)的pipeline來(lái)訓(xùn)練AlphaGo Zero,訓(xùn)練從完全隨機(jī)的行為開(kāi)始,并在沒(méi)有認(rèn)為干預(yù)的情況下持續(xù)3天。
訓(xùn)練過(guò)程中,生成了490萬(wàn)盤自我博弈對(duì)局,每個(gè)MCTS使用1600次模擬,相當(dāng)于每下一步思考0.4秒。下圖顯示了在自我對(duì)弈強(qiáng)化學(xué)習(xí)期間,AlphaGo Zero的表現(xiàn)。整個(gè)訓(xùn)練過(guò)程中,沒(méi)有出現(xiàn)震蕩或者災(zāi)難性遺忘的困擾。
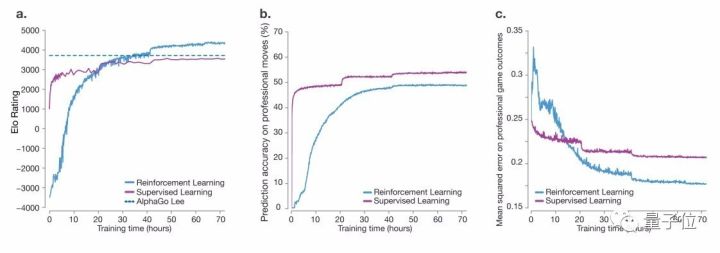
令人驚訝的是,AlphaGo Zero在訓(xùn)練36小時(shí)后,表現(xiàn)就優(yōu)于擊敗李世乭的版本AlphaGo Lee。當(dāng)年那個(gè)版本經(jīng)過(guò)了數(shù)月的訓(xùn)練。AlphaGo Zero使用了4個(gè)TPU,而擊敗李世乭的AlphaGo使用了48個(gè)TPU。
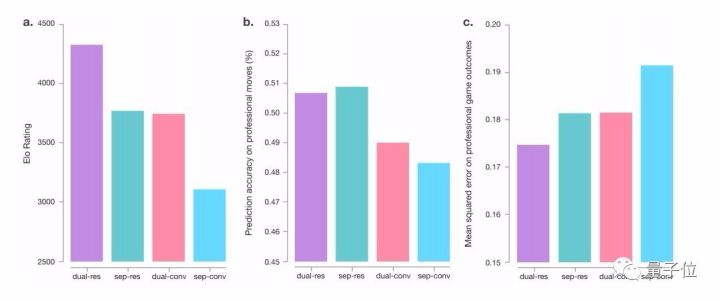
下圖就是AlphaGo Zero和AlphaGo Lee的神經(jīng)網(wǎng)絡(luò)架構(gòu)比較。
論文全文
論文的共同第一作者是David Silver、Julian Schrittwieser、Karen Simonyan。
關(guān)于這篇論文,可以直接從這個(gè)地址下載:
https://deepmind.com/documents/119/agz_unformatted_nature.pdf
DeepMind還放出AlphaGo Zero的80局棋譜,下載地址在此:
https://www.nature.com/nature/journal/v550/n7676/extref/nature24270-s2.zip





















 營(yíng)業(yè)執(zhí)照公示信息
營(yíng)業(yè)執(zhí)照公示信息