AlphaGo Zero的強化學習
上面提到AlphaGo使用了一個神經網絡,這是怎么做到的?
DeepMind使用了一個新的神經網絡fθ,θ是參數。這個神經網絡將原始棋盤表征s(落子位置和過程)作為輸入,輸出落子概率(p, v)= fθ(s)。這里的落子概率向量p表示下一步的概率,而v是一個標量估值,衡量當前落子位置s獲勝的概率。
這個神經網絡把之前AlphaGo所使用的策略網絡和價值網絡,整合成一個單獨的架構。其中包含很多基于卷積神經網絡的殘差模塊。
AlphaGo Zero的神經網絡,使用新的強化學習算法,自我對弈進行訓練。在每個落子位置s,神經網絡fθ指導進行MCTS(蒙特卡洛樹)搜索。MCTS搜索給出每一步的落子概率π。通常這種方式會選出更有效的落子方式。
因此,MCTS可以被看作是一個強大的策略提升operator。這個系統通過搜索進行自我對弈,使用增強的MCTS策略決定如何落子,然后把獲勝z作為價值樣本。
這個強化學習算法的主要理念,實在策略迭代過程中,反復使用這些這些搜索operator:神經網絡的參數不斷更新,讓落子概率和價值(P,v)=fθ(s)越來越接近改善后的搜索概率和自我對弈贏家(π, z)。這些新參數也被用于下一次的自我對弈迭代,讓搜索變得更強大。整個過程如下圖所示。
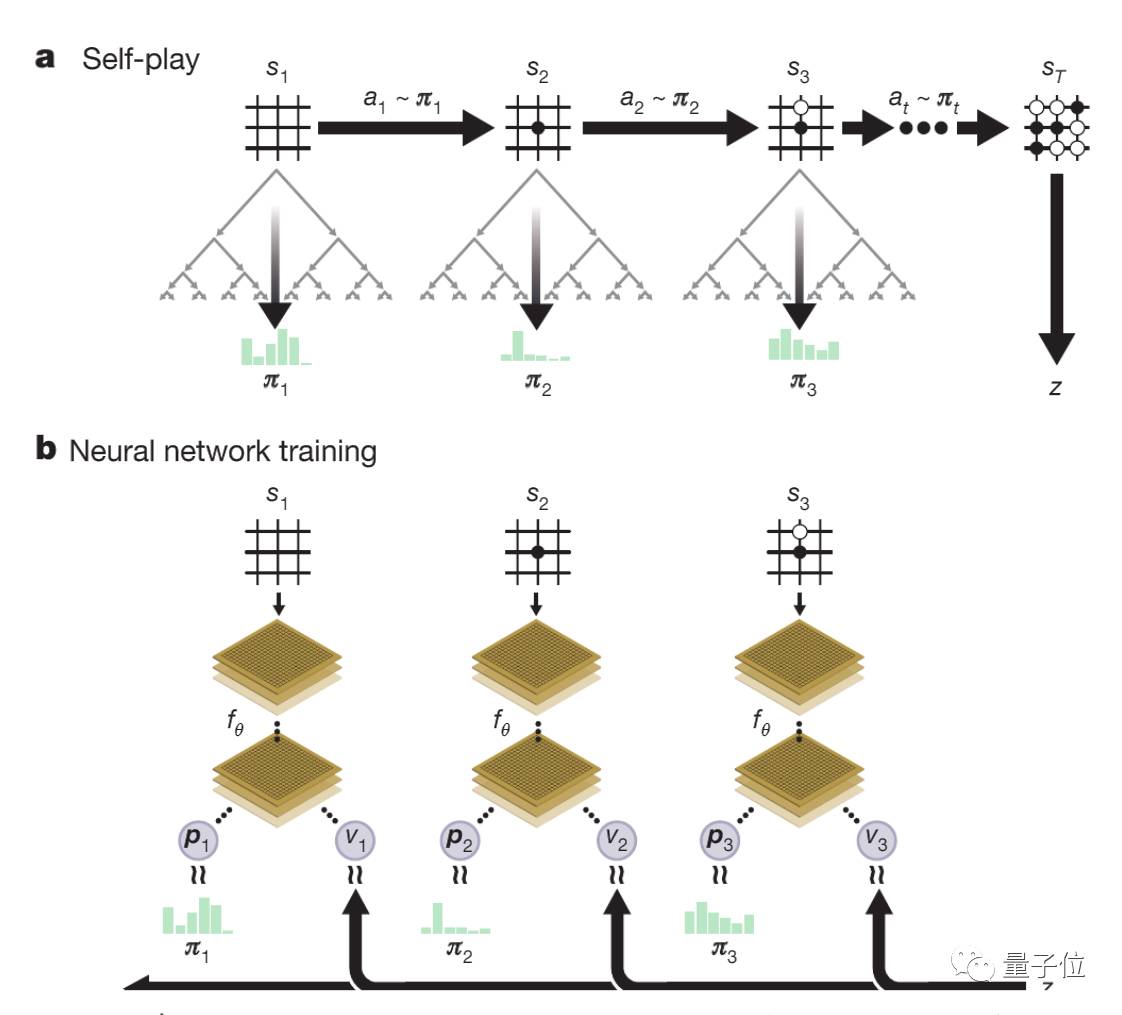
上圖解釋了AlphaGo Zero中的自我對弈強化學習。圖a展示了程序的自我對弈過程。程序在從s1到st的棋局中進行自我對弈,在任意位置st,程序會用最新的神經網絡fθ來執行MCTS αθ,根據MCTS計算出的搜索概率at∼πt選擇落子位置,根據游戲規則來決定最終位置sT,并計算出勝者z。
圖b展示了AlphaGo Zero中的神經網絡訓練過程,神經網絡以棋盤位置st為輸入,將它和參數θ通過多層CNN傳遞,輸出向量Pt和張量值vt,Pt表示幾步之后可能的局面,vt表示st位置上當前玩家的勝率。為了將Pt和搜索概率πt的相似度最大化,并最小化vt和游戲實際勝者z之間的誤差,神經網絡的參數θ會不斷更新,更新后的參數會用到如圖a所示的下一次自我對弈迭代中。
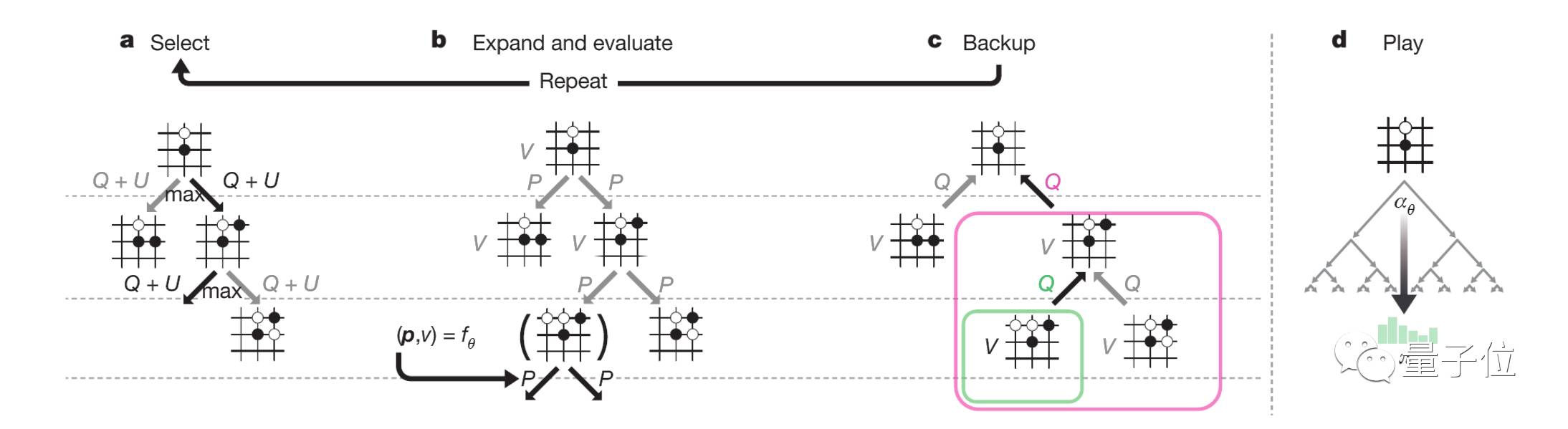
AlpaGo Zero中的MCTS結構如上圖所示,從圖a顯示的選擇步驟可以看出,每次模擬都會通過選擇最大行為價值Q的邊緣,加上置信區間上限U來遍歷樹,U取決于存儲先驗概率P和訪問次數N。
圖b顯示,葉節點擴展和相關位置s的評估都是通過神經網絡(P(s, ·),V(s)) = fθ(s)實現的,P的向量值存儲在s的出口邊緣。





















 營業執照公示信息
營業執照公示信息